
深入剖析HBase架构与原理:从Region到HMaster
前言
随着大数据时代的到来,传统关系型数据库在处理海量数据时显得力不从心。HBase作为Apache Hadoop生态系统中的重要组件,凭借其分布式、可扩展的特性,成为处理PB级数据的理想选择。本文将深入剖析HBase的架构设计和工作原理,帮助读者全面理解HBase如何在分布式环境中高效地存储和处理大规模数据。
HBase架构总览
HBase的架构设计借鉴了Google的BigTable论文,采用主从架构,主要由以下几个核心组件构成:
graph TB
Client[客户端] --> Master[HMaster]
Client --> RS[RegionServer]
Master --> ZK[ZooKeeper]
RS --> ZK
RS --> HDFS[HDFS]
Master --> HDFS
subgraph "管理节点"
Master
ZK
end
subgraph "数据节点"
RS
HDFS
end
style Master fill:#f96,stroke:#333,stroke-width:2px
style RS fill:#9cf,stroke:#333,stroke-width:2px
style ZK fill:#fc9,stroke:#333,stroke-width:2px
style HDFS fill:#9fc,stroke:#333,stroke-width:2px
核心组件及功能
1. HMaster
HMaster是HBase集群的”大脑”,主要负责管理和协调整个集群,其核心功能包括:
- 表管理:处理表的创建、修改和删除操作
- RegionServer管理:监控所有RegionServer的状态,负责Region的分配和负载均衡
- 元数据操作:维护表的元数据信息
- 故障恢复:协调处理RegionServer宕机时的恢复工作
HMaster本身并不参与数据读写操作,而是专注于集群管理,这种设计使得即使HMaster短时间不可用,也不会影响现有数据的读写操作。
2. RegionServer
RegionServer是HBase中实际处理数据读写请求的服务器,每个RegionServer负责管理一部分Region,其主要功能包括:
- 数据存取:处理客户端的读写请求
- Region管理:管理分配给它的所有Region
- 数据压缩:执行数据压缩和合并操作
- 缓存管理:管理内存中的数据缓存(MemStore)和块缓存
RegionServer通常与HDFS的DataNode部署在同一台物理机器上,以实现数据的本地性,降低网络传输开销。
3. ZooKeeper
ZooKeeper作为一个分布式协调服务,在HBase中扮演着至关重要的角色:
- 集群协调:保持集群状态的一致性
- 服务发现:帮助客户端发现可用的HMaster和RegionServer
- 元数据管理:存储集群的元数据信息,如-ROOT-和.META.表的位置
- 故障检测:监控集群节点状态,及时发现节点故障
ZooKeeper通过选举机制确保HMaster的高可用性,当主HMaster发生故障时,备用HMaster可以接管集群管理工作。
4. HDFS
Hadoop分布式文件系统(HDFS)为HBase提供底层的持久化存储:
- 数据存储:存储HBase的数据文件(HFile)和日志文件(WAL)
- 数据复制:通过复制机制确保数据的可靠性
- 大文件优化:针对大文件的读写进行了优化
HBase利用HDFS的高容错性能,确保数据的可靠存储和访问。
数据分片与分布机制
Region:HBase的数据分片单元
Region是HBase表的水平分片,是数据分布和负载均衡的基本单位。一个表最初只有一个Region,随着数据量的增长,会自动分裂成多个Region,分布在不同的RegionServer上。
graph TD
Table[Table] --> R1[Region 1: 开始键 - 键A]
Table --> R2[Region 2: 键A - 键B]
Table --> R3[Region 3: 键B - 结束键]
R1 --> RS1[RegionServer 1]
R2 --> RS2[RegionServer 2]
R3 --> RS2
style Table fill:#f9f,stroke:#333,stroke-width:2px
style R1 fill:#bbf,stroke:#333,stroke-width:1px
style R2 fill:#bbf,stroke:#333,stroke-width:1px
style R3 fill:#bbf,stroke:#333,stroke-width:1px
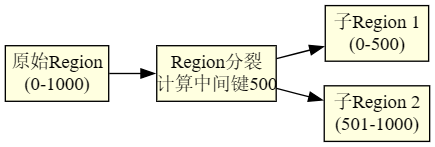
Region分裂过程
当一个Region的大小超过配置的阈值(默认为10GB)时,会触发自动分裂:
- RegionServer检测到Region需要分裂
- 计算中间键(Mid Key),作为分裂点
- 创建两个子Region,分别包含分裂点前后的数据
- 更新元数据表,记录新Region的位置信息
- 关闭父Region,开始提供子Region的服务
Region负载均衡
HMaster会定期检查集群中各RegionServer的负载情况,进行Region的重新分配,以实现负载均衡:
- 启动时平衡:集群启动时,HMaster会尽量均匀地分配Region
- 定期平衡:根据配置的时间间隔,周期性地进行平衡检查
- 手动平衡:管理员可以通过命令手动触发负载均衡
通过这种机制,HBase能够动态适应数据分布的变化,确保集群资源的有效利用。
存储架构与原理
存储层次结构
HBase的存储层次结构如下:
graph TD
Table[表 Table] --> Region1[Region 1]
Table --> Region2[Region 2]
Region1 --> Store1[Store: CF1]
Region1 --> Store2[Store: CF2]
Store1 --> MS1[MemStore]
Store1 --> HF1[HFile 1]
Store1 --> HF2[HFile 2]
MS1 --> HDFS[HDFS存储]
HF1 --> HDFS
HF2 --> HDFS
style Table fill:#f9f,stroke:#333,stroke-width:2px
style Region1 fill:#bbf,stroke:#333,stroke-width:1px
style Store1 fill:#bfb,stroke:#333,stroke-width:1px
style MS1 fill:#fbb,stroke:#333,stroke-width:1px
style HF1 fill:#fbb,stroke:#333,stroke-width:1px
HFile:数据存储文件
HFile是HBase在HDFS上存储数据的文件格式,具有以下特点:
- 块结构:数据以块为单位组织,有利于压缩和随机访问
- 索引机制:多层索引结构,支持快速查找
- 不可变性:一旦写入就不能修改,只能通过新写入来覆盖旧数据
- 排序存储:数据按照RowKey、ColumnFamily、Qualifier和Timestamp排序
1 | +----------------+ |
MemStore:内存存储
MemStore是RegionServer中的内存缓冲区,每个Store都有一个MemStore:
- 写缓存:数据写入HBase时,首先写入MemStore
- 排序存储:内部采用ConcurrentSkipListMap数据结构,保证数据有序
- 定期刷写:当MemStore达到配置的阈值时,会将数据刷写到HDFS上的HFile
- 实时性:提供数据的实时读取能力
BlockCache:读缓存
BlockCache是RegionServer中用于缓存读取的数据块:
- 读缓存:缓存从HDFS读取的数据块
- LRU策略:默认采用LRU(最近最少使用)缓存淘汰策略
- 多级缓存:HBase 2.0引入了多级缓存机制,包括L1(堆内)和L2(堆外)缓存
通过MemStore和BlockCache的配合,HBase实现了高效的读写性能。
WAL:写前日志机制
Write-Ahead Log(WAL)是HBase保证数据可靠性的重要机制:
- 数据安全:在数据写入MemStore之前,先写入WAL日志
- 故障恢复:当RegionServer崩溃时,通过重放WAL日志恢复未刷写到HDFS的数据
- 顺序写入:WAL采用顺序写入方式,性能较高
- 定期滚动:WAL文件会定期滚动,以控制单个文件的大小
sequenceDiagram
participant Client as 客户端
participant RS as RegionServer
participant WAL as Write-Ahead Log
participant MemStore as MemStore
participant HDFS as HDFS/HFile
Client->>RS: 写请求
RS->>WAL: 1. 写入WAL
WAL-->>RS: 确认
RS->>MemStore: 2. 写入MemStore
MemStore-->>RS: 确认
RS-->>Client: 响应成功
Note over MemStore,HDFS: 当MemStore达到阈值
MemStore->>HDFS: 3. 刷写到HFile
存储文件压缩:Compaction
随着数据不断写入,HBase会产生大量小的HFile文件,影响读取性能。为此,HBase引入了Compaction机制:
Minor Compaction(小合并)
- 选择一些较小的相邻HFile文件进行合并
- 频率较高,对性能影响较小
- 不会删除过期或标记删除的数据
Major Compaction(大合并)
- 合并一个Store中的所有HFile文件
- 删除过期数据和标记删除的数据
- 重写所有数据,生成一个大的HFile文件
- 资源消耗大,通常在低峰期进行
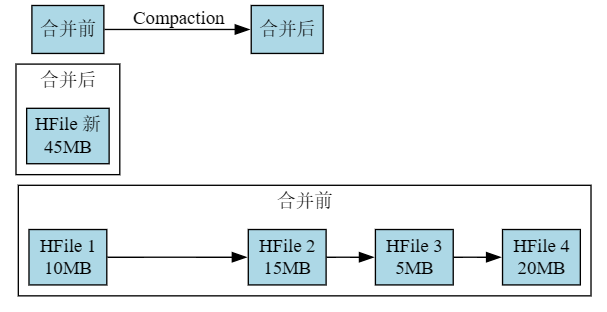
通过Compaction机制,HBase能够保持较好的读取性能,同时清理无效数据,节省存储空间。
数据读写流程
写入流程
客户端写入数据到HBase的完整流程如下:
- 定位Region:客户端查询ZooKeeper和META表,确定数据应写入的Region位置
- 发送请求:客户端将写请求发送到对应的RegionServer
- 写WAL:RegionServer先将数据写入WAL日志
- 写MemStore:数据写入对应的MemStore
- 响应客户端:如果WAL和MemStore都写入成功,则返回成功响应
- 定期刷写:当MemStore达到阈值时,数据异步刷写到HFile
sequenceDiagram
participant Client as 客户端
participant ZK as ZooKeeper
participant META as META表
participant RS as RegionServer
participant WAL as WAL日志
participant MS as MemStore
participant HDFS as HDFS/HFile
Client->>ZK: 1. 查询META表位置
ZK-->>Client: 返回META表位置
Client->>META: 2. 查询目标Region位置
META-->>Client: 返回RegionServer地址
Client->>RS: 3. 发送写请求
RS->>WAL: 4. 写入WAL
WAL-->>RS: 确认
RS->>MS: 5. 写入MemStore
MS-->>RS: 确认
RS-->>Client: 6. 响应成功
Note over MS,HDFS: 当MemStore达到阈值
MS->>HDFS: 7. 刷写到HFile
读取流程
客户端从HBase读取数据的完整流程如下:
- 定位Region:通过ZooKeeper和META表定位目标Region
- 发送请求:客户端将读请求发送到对应的RegionServer
- 检查行锁:确保没有写操作正在修改请求的行
- 读取数据:按照以下顺序查找数据:
- 先查找BlockCache(读缓存)
- 再查找MemStore(写缓存)
- 最后查找HFile(磁盘文件)
- 合并结果:合并从不同地方读取的数据,应用过滤条件
- 返回结果:将最终结果返回给客户端
sequenceDiagram
participant Client as 客户端
participant ZK as ZooKeeper
participant META as META表
participant RS as RegionServer
participant BC as BlockCache
participant MS as MemStore
participant HF as HFile
Client->>ZK: 1. 查询META表位置
ZK-->>Client: 返回META表位置
Client->>META: 2. 查询目标Region位置
META-->>Client: 返回RegionServer地址
Client->>RS: 3. 发送读请求
RS->>BC: 4a. 查找BlockCache
BC-->>RS: 返回结果(可能为空)
RS->>MS: 4b. 查找MemStore
MS-->>RS: 返回结果(可能为空)
RS->>HF: 4c. 查找HFile
HF-->>RS: 返回结果(可能为空)
RS->>RS: 5. 合并结果,应用过滤
RS-->>Client: 6. 返回最终结果
这种多层次的读取策略,确保了HBase能够提供高效的读取性能,同时保证数据的一致性。
HBase高可用性机制
Master高可用
HBase通过多Master机制实现HMaster的高可用:
- 配置多个HMaster,一个Active,其他为Standby
- ZooKeeper负责Master选举和状态监控
- 当Active HMaster故障时,Standby HMaster自动接管
由于HMaster只负责管理操作,即使HMaster短时间不可用,也不会影响现有数据的读写。
RegionServer故障恢复
当RegionServer发生故障时,HBase通过以下步骤恢复:
- ZooKeeper检测到RegionServer会话超时
- HMaster收到通知,确认RegionServer已经宕机
- HMaster将故障RegionServer上的Regions重新分配到其他RegionServer
- 新的RegionServer通过重放WAL日志,恢复未持久化的数据
- 恢复完成后,Regions重新提供服务
sequenceDiagram
participant ZK as ZooKeeper
participant Master as HMaster
participant RS1 as RegionServer 1(故障)
participant RS2 as RegionServer 2
participant WAL as WAL日志
Note over RS1: 发生故障
ZK->>Master: 1. 通知RegionServer 1故障
Master->>Master: 2. 确认故障,开始恢复
Master->>RS2: 3. 分配Region到RS2
RS2->>WAL: 4. 读取WAL日志
RS2->>RS2: 5. 重放WAL,恢复数据
RS2->>Master: 6. 恢复完成,提供服务
Master->>ZK: 7. 更新元数据
这种故障恢复机制,使得HBase能够在节点故障的情况下,仍然保持数据的可用性和一致性。
HDFS数据可靠性
HBase依赖HDFS提供底层数据的可靠性保障:
- HDFS默认将数据块复制为3份,分布在不同的节点
- 当一个数据节点故障时,HDFS自动复制数据块到其他健康节点
- HDFS的NameNode高可用机制确保元数据的可靠性
通过这些机制,HBase能够提供高度可靠的数据存储服务。
HBase性能优化
RowKey设计优化
RowKey设计是HBase性能优化的关键:
- 避免热点:设计散列分布的RowKey,避免数据集中在少数Region
- 可使用加盐、哈希等技术
- 时间戳反转可避免最近数据热点
- 长度控制:RowKey尽量保持短小(10-100字节)
- 减少网络传输和存储开销
- 可以使用压缩编码(如:MD5取前N位)
- 业务关联:将常用的查询条件纳入RowKey设计
- 支持高效的范围扫描
- 避免跨Region查询
1 | # 不良设计:使用递增ID作为RowKey |
内存优化
合理配置RegionServer的内存参数,对HBase性能至关重要:
- MemStore配置:MemStore是写入缓冲区
hbase.regionserver.global.memstore.size:控制全局MemStore大小,默认为堆内存的40%hbase.hregion.memstore.flush.size:单个Region的MemStore刷写阈值
- BlockCache配置:BlockCache是读取缓存
hbase.regionserver.global.blockcache.size:控制BlockCache大小,默认为堆内存的40%- 可使用堆外缓存减轻GC压力
- JVM优化:合理的GC策略
- 推荐使用G1 GC
- 避免长时间的Full GC
表设计优化
合理的表设计也是提升HBase性能的重要手段:
- 列族数量:控制在1-3个
- 过多的列族会增加管理开销
- 每个列族独立刷写和压缩
- 列数量控制:
- 避免超宽表(上万列)
- 考虑列族存储模式,可动态增加列
- 版本数设置:
- 根据业务需求设置合理的版本数
- 过多版本会增加存储和查询开销
读写优化
针对具体的读写场景,可采用以下优化策略:
写入优化
- 批量写入:使用批处理API减少RPC调用
- WAL配置:对非重要数据可考虑关闭WAL
- 关闭自动刷写:特定场景下手动控制刷写时机
读取优化
- Scan缓存:设置合理的caching参数
- 批量获取:使用MultiGet替代多次Get
- 使用过滤器:在服务端过滤数据,减少网络传输
- 启用Bloom过滤器:快速判断某行数据是否存在
实际应用场景
日志存储与分析
HBase在日志存储领域有广泛应用:
- 特点:日志数据量大、写入频繁、基本是追加操作
- 设计要点:
- RowKey可采用”反转时间戳_设备ID”格式
- 使用Scan范围查询快速获取特定时间段日志
- 合理设置TTL自动清理过期日志
时序数据存储
对于物联网、监控等产生的时序数据:
- 特点:数据量巨大、写入频繁、读取通常按时间范围
- 设计要点:
- RowKey可采用”设备ID_反转时间戳”格式
- 使用列族区分不同类型的指标
- 数据预聚合减少查询时的计算量
实时分析系统
HBase作为实时分析系统的数据存储层:
- 特点:需要同时支持高并发写入和复杂查询
- 设计要点:
- 合理设计RowKey支持多维查询
- 预计算和缓存热点数据
- 与计算引擎(如Spark)集成提高分析效率
总结
HBase作为一款强大的分布式列存储数据库,其架构设计充分体现了分布式系统的核心理念:
可扩展性:通过Region水平分片机制,HBase可以线性扩展到数千节点,处理PB级数据。
高可用性:多Master机制、WAL恢复、HDFS数据复制等多重保障,确保服务和数据的高可用。
一致性:通过Region的独占服务和行级原子性,保证数据的一致性。
性能:多级缓存机制、LSM树存储结构、异步批量操作等设计,在海量数据场景下依然保持优秀性能。
HBase的架构设计体现了”简单胜于复杂”的哲学,通过将复杂问题分解为多个简单问题,构建了一个高度可靠、高性能的分布式数据库系统。在大数据时代,HBase已成为处理海量结构化和半结构化数据的标准解决方案之一。
深入理解HBase的架构与原理,不仅有助于更好地使用HBase,也能为我们提供分布式系统设计的宝贵经验和思路。
参考资源
 微信
微信- 支付宝

