
Kafka实际应用与案例:从理论到实践
前言
Apache Kafka作为当今最流行的分布式流处理平台之一,已在众多企业的核心业务系统中扮演着关键角色。从最初LinkedIn内部的消息系统,到如今成为大数据生态系统中不可或缺的组件,Kafka凭借其高吞吐量、可靠性和可扩展性,成功应用于各行各业的实际生产环境。本文将深入探讨Kafka在各领域的具体应用案例,解析其核心架构如何解决实际业务问题,并分享实施过程中的最佳实践与经验教训,帮助读者更好地理解如何在自己的业务场景中合理应用Kafka技术。
Kafka在各行业的应用概览
Kafka因其出色的性能和可靠性,已在多个行业得到广泛应用。下图展示了Kafka在不同行业的应用分布:
pie title Kafka在各行业的应用占比
"互联网" : 32
"金融服务" : 25
"电信" : 15
"零售" : 12
"制造业" : 8
"医疗健康" : 5
"其他行业" : 3
各行业利用Kafka解决的核心问题各有侧重,但主要集中在以下几个方面:数据集成、实时处理、消息传递、日志聚合和事件驱动架构。接下来我们将通过具体案例,详细分析Kafka在这些领域的实际应用。
Kafka在日志聚合与监控中的应用
1. 企业级日志聚合架构
大型企业通常有成百上千的服务器和应用系统,产生海量的日志数据。传统的日志收集方式难以满足实时性和可靠性需求。Kafka作为日志聚合的中心枢纽,可以构建高效可靠的日志处理管道:
graph TD
A[应用服务器集群] -->|日志收集| B[Filebeat/Fluentd]
B -->|发送日志| C[Kafka集群]
C -->|消费日志| D[Elasticsearch]
C -->|消费日志| E[Hadoop/HDFS]
D --> F[Kibana/Grafana]
E --> G[离线分析]
这种架构具有以下优势:
- 解耦日志生产者和消费者
- 缓冲峰值流量,提高系统稳定性
- 支持多种消费方式,满足不同场景需求
- 保证日志数据的可靠性和顺序性
2. 实时监控系统案例
某电商平台使用Kafka构建了全站实时监控系统,该系统每秒处理数十万条监控数据,及时发现并报警系统异常:
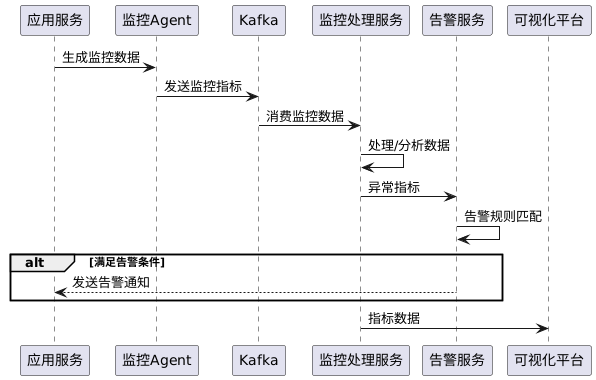
性能优化措施
在该监控系统中,为了确保Kafka能够处理高峰期每秒30万+的监控数据,采取了以下Kafka优化措施:
- 合理分区设计:将监控主题按服务和指标类型划分,配置200+分区
- 批量发送:客户端配置批量发送机制,减少网络开销
- 消息压缩:使用LZ4压缩算法减少网络带宽使用
- 硬件优化:SSD存储、高内存配置提升I/O性能
- 参数调优:根据实际负载调整生产者和消费者参数
3. 全球化日志处理案例
某跨国企业构建了基于Kafka的跨区域日志处理系统,解决了全球业务的日志统一处理问题:
graph TD
A[亚太区应用] -->|区域收集| B[亚太区Kafka]
C[欧洲区应用] -->|区域收集| D[欧洲区Kafka]
E[北美区应用] -->|区域收集| F[北美区Kafka]
B -->|跨区域复制| G[全球中心Kafka]
D -->|跨区域复制| G
F -->|跨区域复制| G
G --> H[全球日志存储]
G --> I[全球分析系统]
该架构采用了Kafka的MirrorMaker工具实现跨区域数据复制,解决了以下挑战:
- 处理网络延迟和跨区域带宽限制
- 保证数据一致性和完整性
- 支持区域级故障隔离
- 实现全球视图的统一分析
Kafka在金融行业的应用
1. 实时交易处理系统
金融行业需要处理大量实时交易数据,同时要求极高的可靠性和一致性。Kafka的持久化和消息保证机制使其成为金融交易系统的理想选择:
graph LR
A[交易网关] --> B[交易前置处理]
B --> C[Kafka交易主题]
C --> D[交易处理服务]
D --> E[核心账务系统]
C --> F[风控系统]
C --> G[实时报表]
C --> H[合规审计]
金融级Kafka配置
在金融交易系统中,Kafka通常需要特殊配置以满足更高的可靠性要求:
| 参数 | 推荐配置 | 说明 |
|---|---|---|
| acks | all | 确保所有副本收到消息 |
| min.insync.replicas | 2 | 至少2个同步副本才能写入 |
| unclean.leader.election.enable | false | 禁止不同步副本成为leader |
| replication.factor | 3 | 三副本存储 |
| log.flush.interval.messages | 较小值 | 增加刷盘频率 |
| auto.create.topics.enable | false | 禁止自动创建主题 |
2. 实际案例:支付系统的Kafka应用
某支付平台使用Kafka构建了高可用的交易处理系统,该系统每天处理数千万笔支付交易:
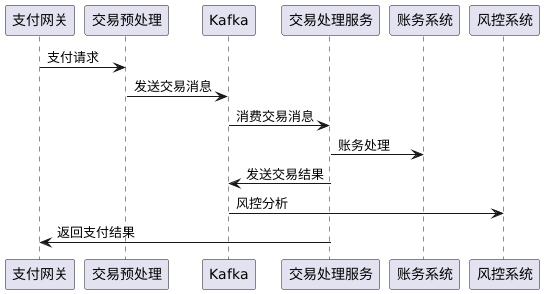
该系统的成功实践包括:
- 消息设计:使用Avro格式定义交易消息,支持模式演化
- 端到端确认:实现从请求到处理的全链路跟踪
- 消息幂等性:通过唯一交易ID确保消息处理幂等性
- 主题分区:按照交易类型和商户划分主题和分区
- 多级监控:构建从Kafka到业务的多层监控告警体系
Kafka在物联网领域的应用
1. 大规模IoT数据处理架构
随着物联网设备的爆发式增长,处理海量设备产生的实时数据成为大挑战。Kafka的高吞吐特性使其成为理想的IoT数据管道:
graph TD
A[IoT设备] -->|MQTT| B[设备网关]
B -->|设备数据| C[Kafka集群]
C -->|实时处理| D[Spark Streaming]
C -->|批处理| E[Hadoop]
C -->|时序存储| F[InfluxDB/TimescaleDB]
D --> G[实时仪表盘]
F --> G
E --> H[离线分析]
IoT场景下的Kafka优化
在物联网场景下,Kafka需要处理大量小消息和突发流量,优化策略包括:
- 合理配置消息批处理参数
- 使用高效序列化格式(如Protobuf)
- 实施消息聚合,减少单条消息开销
- 配置合适的主题保留策略
- 根据数据优先级设置不同服务质量
2. 实际案例:智能工厂的Kafka应用
某制造企业使用Kafka构建了工厂设备监控系统,每天收集和处理超过1亿条设备状态数据:
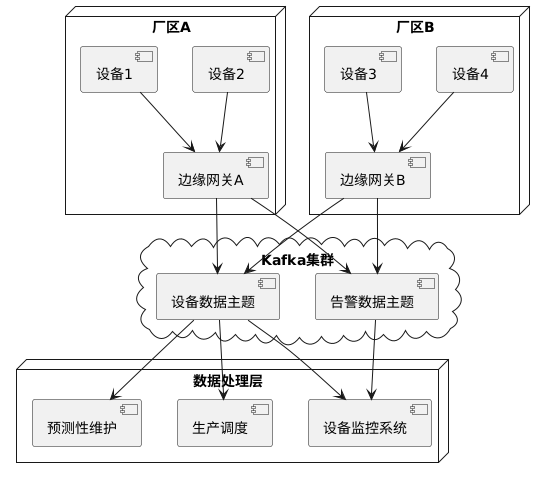
该系统的核心技术点包括:
- 边缘计算:在边缘网关进行初步数据过滤和聚合
- 分层主题设计:按设备类型、数据类型和优先级设计主题
- 动态分区分配:根据设备数量动态调整分区
- 异常处理流程:建立专门的死信队列处理异常数据
- 弹性伸缩:根据工厂生产计划调整Kafka集群资源
Kafka在事件驱动架构中的应用
1. 微服务事件驱动架构
传统的微服务通常采用REST或RPC进行服务间通信,这种同步调用方式容易造成服务间紧耦合和系统脆弱性。基于Kafka的事件驱动架构能很好地解决这些问题:
graph TD
A[用户服务] -->|用户事件| K[Kafka事件总线]
B[订单服务] -->|订单事件| K
C[支付服务] -->|支付事件| K
D[库存服务] -->|库存事件| K
K -->|用户事件| B
K -->|用户事件| C
K -->|订单事件| C
K -->|订单事件| D
K -->|支付事件| B
K -->|支付事件| D
事件驱动架构的优势:
- 服务解耦,提高系统弹性
- 支持异步处理,提升系统吞吐量
- 便于系统扩展,新增服务无需修改现有服务
- 支持事件溯源,方便故障追踪和状态重建
2. 实际案例:电商平台的事件驱动架构
某大型电商平台使用Kafka构建了事件驱动的微服务架构,重构了传统的单体应用:

该平台的Kafka最佳实践:
- 事件标准化:建立统一的事件格式和命名规范
- 事件版本化:支持事件模式演进和向后兼容
- 主题命名规范:如
service.entity.action(例如order.payment.completed) - 消费者失败处理:实施重试策略和死信队列
- 消息追踪系统:建立端到端事件追踪机制
Kafka在大数据实时处理中的应用
1. 实时数据管道架构
传统的数据处理往往是批处理方式,无法满足实时分析需求。Kafka结合大数据技术可以构建高效的实时数据处理管道:
graph LR
A[数据源] -->|数据采集| B[Kafka]
B -->|流处理| C[Spark Streaming/Flink]
B -->|批处理| D[Hadoop/Hive]
C -->|实时结果| E[实时数据存储]
D -->|批处理结果| F[数据仓库]
E --> G[实时仪表盘]
F --> H[BI报表]
这种架构的优势:
- 统一的数据入口,减少系统复杂性
- 支持实时和批处理双模式
- 数据缓冲,避免下游系统过载
- 历史数据回放能力
2. 实际案例:用户行为分析平台
某互联网公司基于Kafka构建了用户行为分析平台,该平台每天处理超过10亿条用户行为数据:
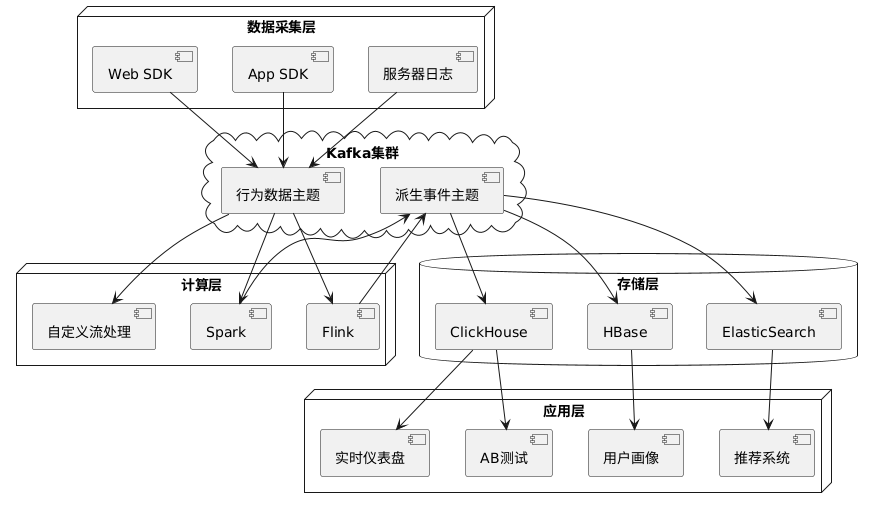
该平台的核心实践:
- 分层主题设计:原始数据、清洗数据、聚合数据分别存储
- 动态计算编排:支持按需定义分析任务
- 计算资源隔离:关键业务和非关键业务使用不同消费组
- 全链路监控:从数据采集到存储的全程监控
- 数据质量控制:在数据流转各环节实施数据质量检查
Kafka集群治理与最佳实践
1. 大规模Kafka集群架构
随着业务增长,Kafka集群规模不断扩大,需要合理的架构设计和运维策略:
graph TD
A[负载均衡层] --> B[Kafka集群A-生产环境]
A --> C[Kafka集群B-生产环境]
B --> D[ZooKeeper集群A]
C --> E[ZooKeeper集群B]
B --> F[监控系统]
C --> F
G[管理平台] --> B
G --> C
大规模集群的设计考虑:
- 按业务域划分集群,避免单集群过大
- 跨区域部署,提高可用性
- 实施严格的容量规划和扩展策略
- 建立自动化运维体系
2. Kafka集群性能调优实践
在实际生产环境中,Kafka集群性能调优是一项关键工作。以下是一个真实案例中的调优经验:
| 调优前指标 | 调优措施 | 调优后指标 | 提升比例 |
|---|---|---|---|
| 生产吞吐:150MB/s | 优化生产者批量配置 | 生产吞吐:280MB/s | 86.7% |
| 消费吞吐:180MB/s | 调整消费者线程和批量 | 消费吞吐:320MB/s | 77.8% |
| 延迟:250ms | 网络和磁盘I/O优化 | 延迟:120ms | 52.0% |
| 磁盘使用效率:65% | 调整日志压缩和分段 | 磁盘使用效率:82% | 26.2% |
关键调优参数和最佳实践:
生产者优化:
- batch.size:根据消息大小调整,通常16-128KB
- linger.ms:权衡延迟和吞吐,生产环境5-100ms
- compression.type:根据CPU和网络带宽选择合适压缩算法
消费者优化:
- fetch.min.bytes:避免频繁小批量拉取
- fetch.max.wait.ms:平衡延迟和吞吐
- max.poll.records:根据处理能力调整单次拉取记录数
Broker优化:
- num.io.threads:调整为CPU核心数的2倍
- num.network.threads:根据客户端连接数调整
- log.flush.interval.messages:权衡性能和数据安全性
3. 实际案例:跨数据中心Kafka架构
某跨国企业构建了跨数据中心的Kafka架构,实现了全球业务的统一消息平台:
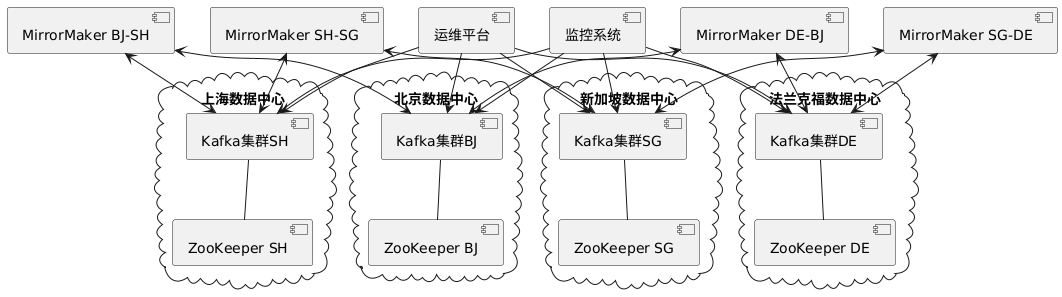
该架构的关键设计:
- 区域内本地性:本地应用优先使用本地集群
- 数据选择性复制:只复制必要的跨区域数据
- 复制拓扑优化:根据网络质量设计复制路径
- 元数据统一管理:统一的主题管理和配置
- 全球化监控:端到端延迟和复制状态监控
总结
通过本文的分析和案例分享,我们可以看到Kafka作为一款功能强大的分布式流处理平台,在各个行业和应用场景中都发挥着重要作用。从日志聚合到事件驱动架构,从金融交易到物联网数据处理,Kafka的高吞吐、可靠性和可扩展性特性使其成为构建实时数据处理系统的理想选择。
在实际应用中,合理的架构设计、系统调优和运维管理是成功利用Kafka的关键。随着Kafka技术的不断发展和完善,特别是Kafka Streams和ksqlDB等流处理工具的加入,Kafka生态系统将能够支持更丰富的应用场景,为企业数据处理提供更全面的解决方案。
对于计划使用Kafka的开发者和架构师,建议深入理解Kafka的核心概念和工作原理,根据业务特点选择合适的架构模式,并通过持续的监控和优化,充分发挥Kafka的性能潜力,构建高效、可靠的数据处理系统。
参考资源
 微信
微信- 支付宝

