
Kafka核心功能与技术特性:深入理解分布式消息队列
前言
随着大数据时代的到来,企业面临着前所未有的数据处理挑战。从物联网设备产生的传感器数据,到用户在网站和应用上的行为数据,再到业务系统间的实时通信需求,传统的数据处理架构已经难以应对。Apache Kafka作为一个分布式流处理平台,凭借其高吞吐量、可扩展性和容错能力,已成为构建实时数据管道和流处理应用的首选技术。本文将深入探讨Kafka的核心功能与技术特性,帮助读者全面理解这一强大的分布式消息队列系统。
Kafka的技术架构
整体架构设计
Kafka的设计理念是简单而高效,核心架构可以用以下图表表示:
graph TD
A[生产者] --> B[Broker集群]
B --> C[消费者]
B <--> D[ZooKeeper/KRaft]
subgraph "Broker集群"
E[Broker 1]
F[Broker 2]
G[Broker 3]
end
Kafka集群由多个Broker(服务器节点)组成,每个Broker负责管理一部分分区数据。生产者向Broker发送消息,消费者从Broker读取消息。在早期版本中,Kafka使用ZooKeeper管理集群元数据,而在较新的版本中,正逐步过渡到内置的KRaft模式。
核心组件
1. Topic与Partition
Topic是Kafka中最基本的数据组织形式,可以理解为一类消息的集合。每个Topic被分为多个Partition,实现了数据的分布式存储和并行处理。
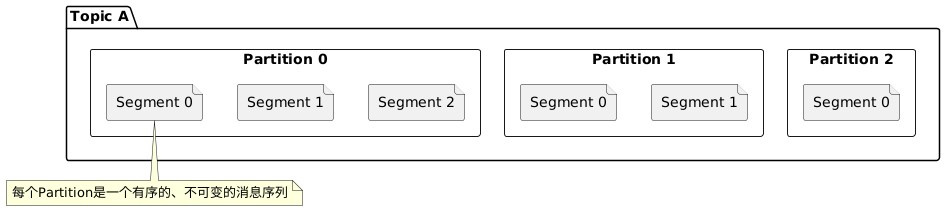
Partition的关键特性:
- 顺序保证:每个Partition内的消息是严格按照追加顺序存储的,保证了消息的顺序性。
- 并行处理:多个Partition可以被不同的消费者并行处理,提高了吞吐量。
- 分布式存储:不同Partition可以分布在不同的Broker上,实现了负载均衡。
- 可扩展性:通过增加Partition数量,可以线性扩展处理能力。
2. Producer(生产者)
Producer负责将消息发布到Kafka集群中的特定Topic。它通过网络将消息发送到Broker,并可以选择不同的分区策略。
1 | // Producer配置示例 |
Producer的分区策略包括:
- 基于Key的哈希分区(默认)
- 轮询(Round-Robin)分区
- 自定义分区策略
3. Consumer(消费者)
Consumer从Kafka集群中订阅并消费消息。多个Consumer可以组成Consumer Group,共同消费一个Topic的数据。
graph TD
T[Topic X] --> P1[Partition 0]
T --> P2[Partition 1]
T --> P3[Partition 2]
T --> P4[Partition 3]
subgraph "Consumer Group A"
P1 --> C1[Consumer 1]
P2 --> C1
P3 --> C2[Consumer 2]
P4 --> C2
end
subgraph "Consumer Group B"
P1 --> C3[Consumer 3]
P2 --> C4[Consumer 4]
P3 --> C5[Consumer 5]
P4 --> C5
end
Consumer Group的关键特性:
- 水平扩展:通过增加Consumer数量,可以提高消费能力。
- 负载均衡:同一Consumer Group内的Consumer平均分配Partition。
- 故障容错:当一个Consumer失败时,其负责的Partition会被重新分配给组内其他Consumer。
4. Broker(服务器节点)
Broker是运行Kafka服务的节点,负责接收和处理Producer的请求,存储消息数据,并响应Consumer的读取请求。
Broker的核心功能:
- 消息存储与管理:管理Topic的Partition,存储消息数据。
- 副本管理:维护Partition的多个副本,确保数据可靠性。
- Leader选举:在副本间选择Leader,处理读写请求。
- 消费者组管理:跟踪消费者组的消费位置(offset)。
核心技术特性
1. 高吞吐量的秘密
Kafka以其惊人的吞吐量而闻名,能够处理每秒数百万条消息。这一性能优势源于多种设计决策:
1.1 日志存储结构
Kafka使用追加写(append-only)的日志文件作为基本存储单元,所有操作都是顺序读写,避免了随机I/O的性能开销。
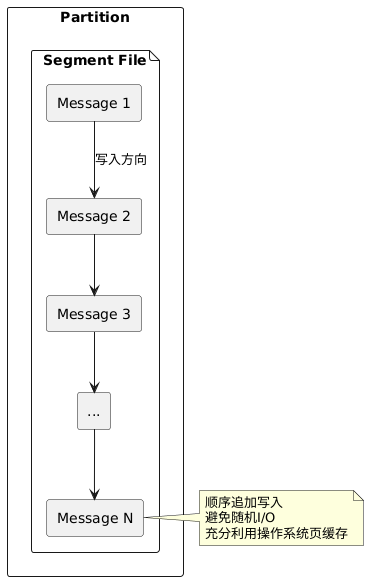
1.2 零拷贝技术
Kafka使用零拷贝(Zero-Copy)技术优化网络传输,当消费者从Broker读取数据时,数据直接从磁盘文件传输到网络通道,无需经过应用程序内存。
| 传统数据传输 | 零拷贝技术 |
|---|---|
| 磁盘→PageCache→应用程序→Socket缓冲区→网卡 | 磁盘→PageCache→网卡 |
| 4次上下文切换 | 2次上下文切换 |
| 4次数据拷贝 | 2次数据拷贝(不涉及CPU) |
1.3 批处理机制
Kafka的Producer会将多条消息打包成一个批次一起发送,减少网络传输次数和开销。
1 | // 批处理配置 |
1.4 页缓存利用
Kafka重度依赖操作系统的页缓存,而不是JVM堆内存,避免了GC带来的性能影响,并实现了数据的快速访问。
2. 数据可靠性保障
2.1 副本机制
为了确保数据不会丢失,Kafka为每个Partition维护多个副本,分布在不同的Broker上。
graph TD
A[Producer] --> B[Leader Replica]
B --> C[Follower Replica 1]
B --> D[Follower Replica 2]
subgraph "Partition"
B
C
D
end
E[Consumer] --> B
副本角色:
- Leader副本:负责处理所有的读写请求。
- Follower副本:从Leader复制数据,不处理客户端请求。当Leader失效时,Follower可被选为新Leader。
- ISR(In-Sync Replicas):与Leader保持同步的副本集合。
2.2 持久化机制
Kafka将消息持久化到磁盘,确保即使在服务器崩溃后也能恢复数据。
1 | // 持久化配置(Broker端) |
2.3 消息确认机制
Producer可以配置消息确认级别(acks),控制消息发送的可靠性:
- acks=0:不等待确认,可能丢失数据但性能最高。
- acks=1:等待Leader确认,较好的性能和可靠性平衡。
- acks=all:等待所有ISR副本确认,可靠性最高但性能较低。
3. 分布式协调与高可用性
3.1 ZooKeeper/KRaft的作用
传统上,Kafka使用ZooKeeper来管理集群状态和协调分布式操作:
- Broker注册:跟踪活跃的Broker。
- Topic管理:存储Topic配置。
- Leader选举:当Broker故障时,协调Leader选举。
- 消费者组管理:跟踪消费者组成员和消费偏移量。
从Kafka 2.8开始,引入了KRaft模式,旨在移除对ZooKeeper的依赖,简化架构。
3.2 Leader选举
当一个Broker失效后,它负责的Leader分区需要选举新的Leader。选举过程如下:
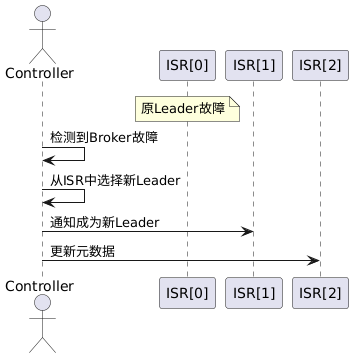
4. 消息语义保证
Kafka提供三种消息传递语义:
4.1 最多一次(At-most once)
消息可能会丢失,但绝不会重复处理。
- 适用场景:可接受数据丢失,如日志收集。
4.2 至少一次(At-least once)
消息不会丢失,但可能会重复处理。
- 配置:Producer设置retries > 0,acks=all。
- 适用场景:不能接受数据丢失,但可以处理重复,如计费系统。
4.3 精确一次(Exactly once)
消息既不会丢失也不会重复处理。
- 实现方式:通过事务API或Kafka Streams的处理保证。
- 适用场景:金融交易、计数统计等。
1 | // 事务Producer示例 |
5. 流处理能力
除了作为消息队列,Kafka还提供强大的流处理功能:
5.1 Kafka Streams API
Kafka Streams是一个客户端库,用于构建实时流处理应用:
1 | // Kafka Streams示例 |
5.2 Connect API
Kafka Connect提供了一种标准方式,用于将Kafka与外部系统(如数据库、搜索引擎)集成:
1 | { |
实际应用案例
1. 日志聚合与分析
集中收集分布式系统中的日志数据,实时处理并存储到HDFS或Elasticsearch等系统中。
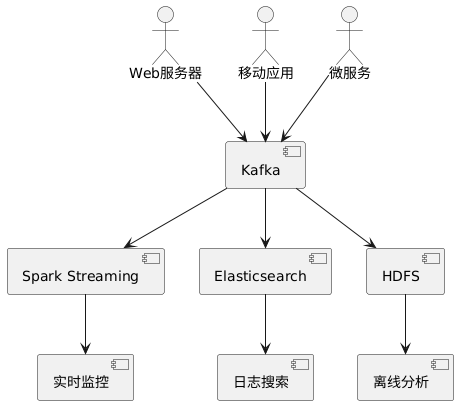
2. 事件溯源架构
使用Kafka作为事件存储,记录所有状态变更事件,支持系统状态重建和事件回放。
sequenceDiagram
Client->>Service: 执行命令
Service->>Kafka: 发布事件
Service->>Client: 返回结果
Kafka->>Event Processor: 消费事件
Event Processor->>View Store: 更新视图
Client->>View Store: 查询数据
3. 实时数据管道
构建从数据源到目标系统的实时数据管道,实现数据的ETL(提取、转换、加载)。
graph LR
A[数据源] --> B[Kafka Connect Source]
B --> C[Kafka]
C --> D[流处理]
C --> E[Kafka Connect Sink]
D --> C
E --> F[目标系统]
4. 微服务通信
使用Kafka作为微服务间的异步通信中间件,实现服务解耦和可靠通信。
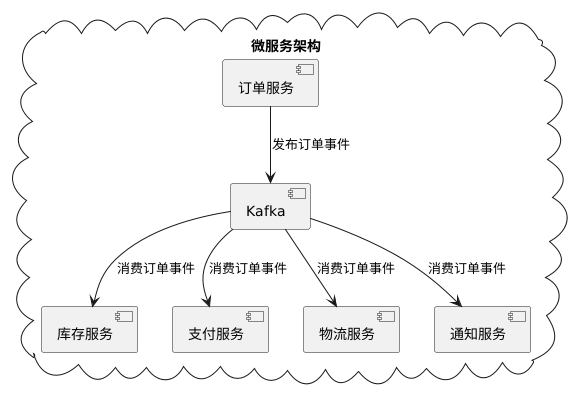
性能调优最佳实践
1. Producer端优化
- 批处理大小:增加
batch.size和linger.ms以提高吞吐量。 - 压缩:启用
compression.type(如snappy、lz4)减少网络带宽。 - 缓冲区大小:调整
buffer.memory以适应高吞吐量场景。 - 幂等性:启用
enable.idempotence=true防止重复发送。
2. Broker端优化
| 参数 | 建议值 | 说明 |
|---|---|---|
| num.network.threads | 3+ | 处理网络请求的线程数 |
| num.io.threads | 8+ | 处理磁盘I/O的线程数 |
| socket.send.buffer.bytes | 102400 | 套接字发送缓冲区大小 |
| socket.receive.buffer.bytes | 102400 | 套接字接收缓冲区大小 |
| log.flush.interval.messages | 10000 | 强制刷新前的消息数 |
| log.retention.hours | 168 | 日志保留时间(小时) |
3. Consumer端优化
- 批量获取:增加
max.poll.records以减少拉取请求次数。 - 提交频率:调整
auto.commit.interval.ms平衡性能和可靠性。 - 并行处理:增加消费者数量(不超过分区数)提高并行度。
4. 分区数量设置
分区数量是影响Kafka性能的关键因素:
1 | 分区数 = max(消费者数量, 目标吞吐量 / 单分区吞吐量) |
- 过少分区限制并行度
- 过多分区增加资源开销和故障恢复时间
5. 监控指标
关键监控指标包括:
- 消息吞吐量:生产和消费的消息数/秒
- 请求延迟:生产和获取请求的响应时间
- 网络吞吐量:进出的网络流量
- 分区ISR状态:同步副本数
- 消费者滞后:消费者落后生产者的消息数
总结
Apache Kafka作为一个高性能、可扩展的分布式流处理平台,通过其独特的设计和强大的功能,成功解决了大规模数据处理的诸多挑战。从其核心的日志存储架构,到分区和副本机制,再到丰富的客户端API,Kafka为现代数据架构提供了强大的基础设施。
随着数据驱动决策的普及和实时处理需求的增长,掌握Kafka的核心功能和技术特性变得尤为重要。通过本文的深入探讨,希望读者能够更全面地理解Kafka的工作原理,并在自己的项目中更好地应用这一强大工具。
无论是构建实时数据管道,还是实现微服务通信,或是开发流处理应用,Kafka都能提供可靠、高效的解决方案。随着Apache Kafka生态系统的不断发展,它在大数据和分布式系统领域的重要性将继续增长。
参考资料
 微信
微信- 支付宝

